[C#] NSoupライブラリを利用してXMLとHTMLをパーシングする方法
こんにちは。明月です。
この投稿はC#でNSoupライブラリを利用してXMLとHTMLをパーシングする方法に関する説明です。
最近、プログラムを作成する時に環境設定ファイルとしてXMLを利用することがあります。以前はXPathを利用してXMLを探索して値を取得しましたが、JQueryのライブラリが登場してCssSelectorエンジン(Sizzle)の概念が生じ、classやidなどのアトリビュートで検索する方法ができました。
NSoupライブラリはXMLやHTML形式にあるファイルやデータをCssSelectorで探索するライブラリです。
個人的にXPathはXMLを探索する時にもっと明確に検索ができますが、Javascriptや様々でCssSelectorをよく使う今はCssSelectorタイプで探索するほうがもっとしやすくなったと思います。
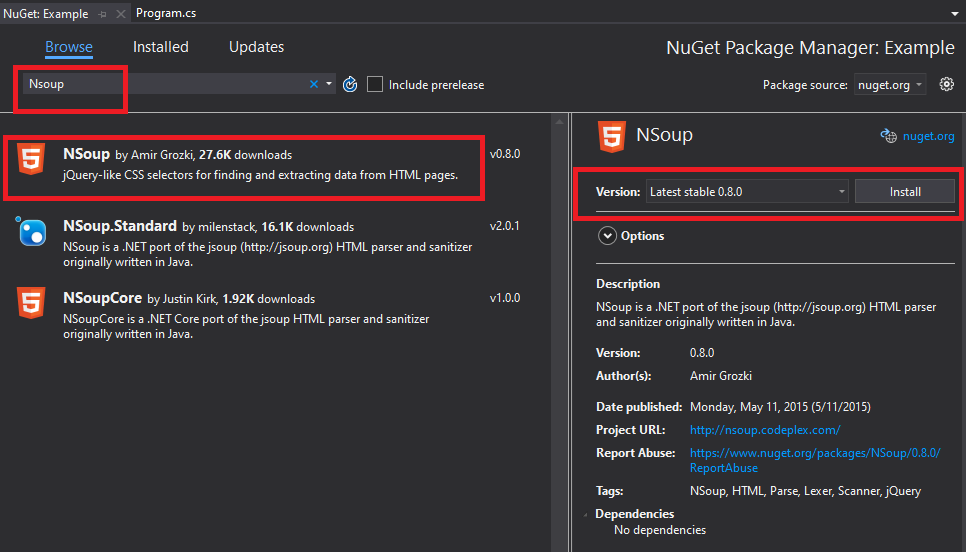
Visual StudioでNSoupライブラリを使うためにNugetを利用してライブラリをダウンロード及び連結しましょう。
私のブログで検索エンジンに登録するようなRSSファイルがあります。

それをNSoupライブラリを利用してタイトルだけ取得します。
using System;
using System.IO;
// HttpWebRequestクラスを利用するため
using System.Net;
// NSoupライブラリ
using NSoup;
using NSoup.Nodes;
class Program
{
// ウェブページからHtmlファイルを取得するための関数。
public static string GetRequest(String url)
{
// HttpWebRequestでウェブサーバに接続する。
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
// 取得メソッドはGetだ。
request.Method = "GET";
// 接続する。
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
// ストリームを取得する。
using (StreamReader reader = new StreamReader(response.GetResponseStream()))
{
// HtmlファイルをStringタイプに返却する。
return reader.ReadToEnd();
}
}
}
// 実行関数。
static void Main(string[] args)
{
// 私のブログのrssのURLに接続する。
var html = GetRequest("https://www.nowonbun.com/rss");
// html形式のStringをパーシングする。
Document doc = NSoupClient.Parse(html);
// item タグを取得する。
var element = doc.Select("item");
// elementは複数で取得するので繰り返してコンソールに出力する。
foreach (var ele in element)
{
// Titleのノードテキストを出力する。
Console.WriteLine(ele.Select("title").Text);
}
// css Selectみたいにitemタグの直下のdescriptionタグを検索する。
element = doc.Select("item > description");
// elementは複数で取得するので繰り返してデータを書き直す。
foreach (var ele in element)
{
ele.Text("Hello world");
}
// コンソールに出力する。
Console.WriteLine(doc.ToString());
Console.WriteLine("Press any key...");
Console.ReadKey();
}
}
上のxmlファイルを取得してitemのtitleタグのデータをコンソールに出力しました。 Jquryでelement探索することと同じ方法で探索が可能です。
NSoupの場合は探索だけではなく、書き直し機能もあります。
上のdescriptionのテキストを「Hello world」に書き直しました。そのあと、コンソールにxmlを出力しました。
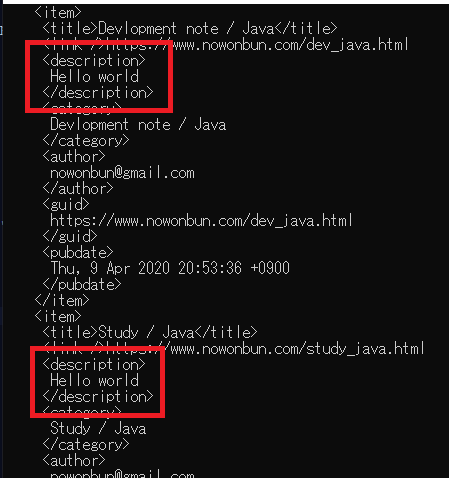
descriptionの部分が「Hello world」になっています。
ここまでC#でNSoupライブラリを利用してXMLとHTMLをパーシングする方法に関する説明でした。
ご不明なところや間違いところがあればコメントしてください。
- [C#] Stringの補間式(interpolation)2020/04/27 20:39:57
- [C#] Newtonsoft.JSONライブラリを利用してJsonデータ構造を扱う方法2020/04/23 20:19:53
- [C#] EMailを送信する方法(System.Net.Mail)2020/04/22 19:00:42
- [C#] ini環境ファイルを使う方法2020/04/22 00:09:39
- [C#] 環境設定ファイルを扱う方法(System.Configuration)2020/04/20 19:37:57
- [C#] Reflectionを利用してクラス複製する方法2020/04/17 00:34:33
- [C#] XMLをXPathを利用してデータを取得する方法2020/04/16 00:47:17
- [C#] NSoupライブラリを利用してXMLとHTMLをパーシングする方法2020/04/14 19:34:15
- [C#] 日付フォーマット2020/04/09 20:53:20
- [C#] ログライブラリ(log4net)を設定する方法2020/04/08 13:04:22
- [C#] Zipの圧縮ファイルを解凍するコードを作成する方法2020/04/07 11:17:44
- [C#] Zip圧縮コードを作成する方法2020/04/06 14:56:13
- [C#] 数字フォーマット(お金表示及び小数点以下表示)2020/04/03 00:38:37
- [C#] コマンド(cmd)を実行する方法(Processクラス)2020/03/31 07:15:40
- [C#] FTPに接続してファイルダウンロード、アップロードする方法2020/03/27 19:20:14
- check2024/04/10 19:03:53
- [Java] 64.Spring bootとReactを連結する方法(Buildする方法)2022/03/25 21:02:18
- [Javascript] Node.jsをインストールしてReactを使う方法2022/03/23 18:01:34
- [Java] 63. Spring bootでcronスケジューラとComponentアノテーション2022/03/16 18:57:30
- [Java] 62. Spring bootでWeb-Filterを設定する方法(Spring Security)2022/03/15 22:16:37
- [Java] JWT(Json Web Token)を発行、確認する方法2022/03/14 19:12:58
- [Java] 61. Spring bootでRedisデータベースを利用してセッションクラスタリング設定する方法2022/03/01 18:20:52
- [Java] 60. Spring bootでApacheの連結とロードバランシングを設定する方法2022/02/28 18:45:48
- [Java] 59. Spring bootのJPAでEntityManagerを使い方2022/02/25 18:27:48
- [Java] 58. EclipseでSpring bootのJPAを設定する方法2022/02/23 18:11:10
- [Java] 57. EclipseでSpring bootを設定する方法2022/02/22 19:04:49
- [Python] Redisデータベースに接続して使い方2022/02/21 18:23:49
- [Java] Redisデータベースを接続して使い方(Jedisライブラリ)2022/02/16 18:13:17
- [C#] Redisのデータベースを接続して使い方2022/02/15 18:46:09
- [CentOS] Redisデータベースをインストールする方法とコマンドを使い方2022/02/14 18:33:07